

在工作中遇到count(*)、count(1)、count(col) ,可能会让你分不清楚,都是计数,干嘛这么搞这么多东西。
count 作用
COUNT(expression):返回查询的记录总数,expression 参数是一个字段或者 * 号。
测试
MySQL版本:5.7.29
创建一张用户表,并插入一百万条数据,其中gender字段有五十万行是为null值的
CREATE TABLE `users` (
`Id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` varchar(32) DEFAULT NULL COMMENT '名称',
`gender` varchar(20) DEFAULT NULL COMMENT '性别',
`create_date` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`Id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='用户表';
复制代码count(*)
在 MySQL 5.7.18 之前,通过扫描聚集索引来InnoDB处理 语句。SELECT COUNT( *)从 MySQL 5.7.18 开始, 通过遍历最小的可用二级索引来InnoDB处理SELECT COUNT( *)语句,除非索引或优化器提示指示优化器使用不同的索引。如果二级索引不存在,则扫描聚集索引。 大概意思就是有二级索引的情况下就使用二级索引,如果有多个二级索引优先选择最小的那个二级索引来降低成本,没有二级索引使用聚集索引。 下面通过测试来验证这些观点。
- 首先,在只有Id这一个主键索引的情况下查询执行计划,

 可以看到,type是index也就是使用了索引,key是PRIMARY就是使用了主键索引,key_len=8。
可以看到,type是index也就是使用了索引,key是PRIMARY就是使用了主键索引,key_len=8。 - 其次在name字段上加上索引,再次使用执行计划查看
 可以看到同样使用了索引,只不过索引用的是name字段的索引,key_len=99。
可以看到同样使用了索引,只不过索引用的是name字段的索引,key_len=99。 - 然后在保留name字段索引的情况下给create_date字段也加上索引,再次查看执行计划
 可以看到这次使用的是create_date字段的索引了,key_len=6。
可以看到这次使用的是create_date字段的索引了,key_len=6。
不管上述是使用了哪个索引,其最后查询到的总行数都是一百万条,无论它们是否包含 NULL值。
count(1)
count(1) 和count(*) 执行查询结果一样,最终也是返回一百万条数据,无论它们是否包含 NULL值。
count(col)
count(col) 统计某一列的值,又分为三种情况:
count(id): 统计id
和count(*) 执行查询结果也是一样,最终也是返回一百万条数据.
count(index col):统计带索引的字段
以count(name)进行查询,执行计划如下:

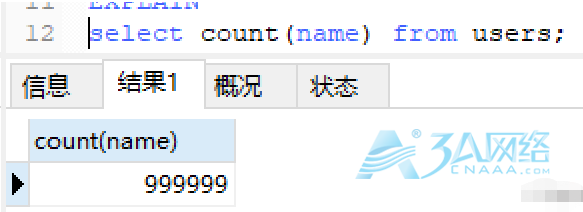
可以看到用的是索引字段进行统计,索引也命中了。 把一列中的name字段置为NULL,再进行count查询,结果返回999999
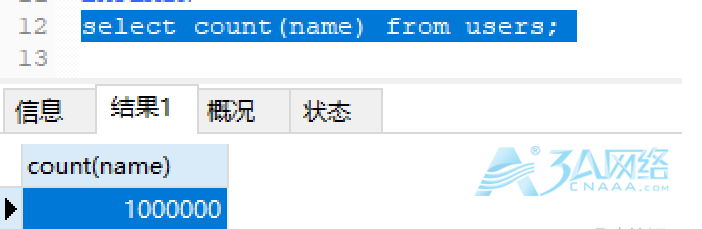
再把这列的NULL值置为空字符串,再进行count查询,结果返回1000000
所以,综上简单的使用索引字段统计行数能够命中索引,并且只统计不为NULL值的行数。
count(normal col):统计不带索引的字段
统计不带索引的字段的话就不会使用索引,而且也是只统计不为NULL值的行数。 
count(1)和count(*)取舍
之前也不知道在哪看到的或听说的,count(1) 比count(*) 效率高,这是错误的认知,官网上有这么一句话,InnoDB handles SELECT COUNT( *) and SELECT COUNT(1) operations in the same way. There is no performance difference. 翻译过来就是,InnoDB以同样的方式处理SELECT COUNT( *)和SELECT COUNT(1) 操作,没有性能差异。
对于MyISAM表, 如果从一个表中检索,没有检索到其他列并且没有 子句,COUNT(*)则优化为非常快速地返回 ,此优化仅适用于MyISAM 表,因为为此存储引擎存储了准确的行数,并且可以非常快速地访问。 COUNT(1)仅当第一列定义为 时才进行相同的优化NOT NULL。—-来自MySQL官网 这些优化都是建立在没有where 和 group by的前提下的。
阿里开发规范中也提到  所以在开发中能用count(*) 就用count( *).
所以在开发中能用count(*) 就用count( *).
文章来源:https://www.cnaaa.net,转载请注明出处:https://www.cnaaa.net/archives/6613

