

我们经常会谈到数据库慢查询。那么什么是数据库慢查询以及导致数据库慢查询的常见原因,以及对应的解决方法。

1、什么是数据库慢查询
数据库慢查询,就是查询时间超过了我们设定的时间的语句。可以通过语句查看设定的时间:
show variables like 'long%';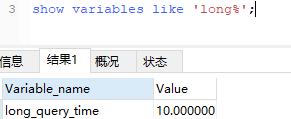
默认的设定时间是10秒,也可以通过下面这个语句修改默认的设定时间:
set long_query_time=0.0001;2、MySQL 慢查询的相关参数解释
slow_query_log :是否开启慢查询日志,1表示开启,0表示关闭
log-slow-queries :旧版(5.6以下版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
slow-query-log-file:新版(5.6及以上版本)MySQL数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
long_query_time :慢查询阈值,当查询时间多于设定的阈值时,记录日志。
log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。
log_output:日志存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到mysql3、慢查询日志配置
默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的,可以通过设置slow_query_log的值来开启,如下所示:
show variables like 'slow_query%'; -- 慢查询
show variables like 'long_query_time'; -- 查询时间设置
show variables like '%slow_query_log%';-- 查看慢查询的日志配置
SET GLOBAL slow_query_log = 'ON'; ---开启慢查询日志
show variables like 'log_queries_not_using_indexes'; --查看未使用索引的
set global log_queries_not_using_indexes=1; -- 未使用索引的查询也被记录到慢查询日志中
show global status like '%slow_queries%';-- 查询慢查询记录4、最大连接数的查看与设置
查看最大连接数:
show variables like '%max_connections%'; -- 上限连接数 SHOW GLOBAL STATUS LIKE 'Max_used_connections' -- 服务响应的最大连接数
比较理想的设置:Max_used_connections / max_connections * 100% ≈ 85%,即最大连接数占上限连接数的85%左右,如果发现比例在10%以下,MySQL服务器连接数上限设置的过高了。
修改最大连接数:
set GLOBAL max_connections = 500;列出MySQL服务器运行各种状态值:
SHOW GLOBAL STATUS;5、常见的慢查询原因及优化
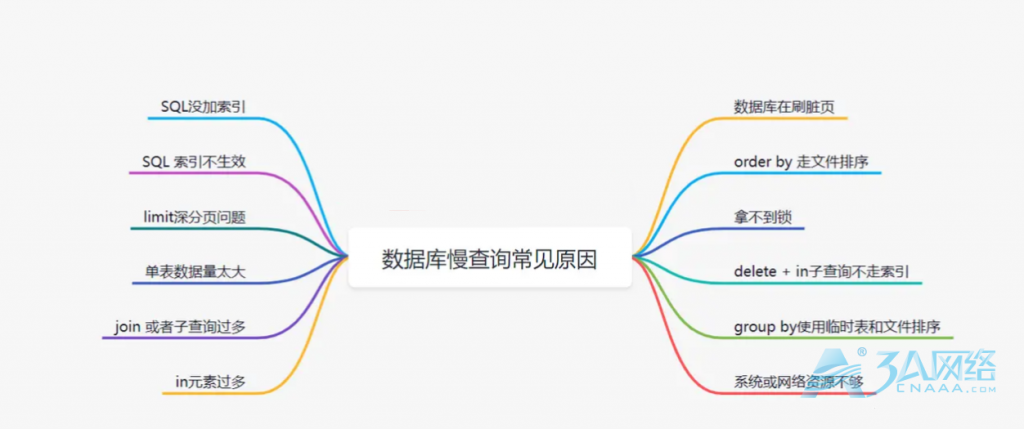
1. SQL没加索引
很多时候,我们的慢查询,都是因为没有加索引。如果没有加索引的话,会导致全表扫描的。因此,应考虑在where的条件列,建立索引,尽量避免全表扫描。
反例:select * from user_info where name =正例:
//添加索引 alter table user_info add index idx_name (name);2. SQL 索引不生效
有时候我们明明加了索引了,但是索引却不生效。在哪些场景,索引会不失效呢?主要有以下几大经典场景:
2.1 优化器选错了索引
MySQL 中一张表是可以支持多个索引的。你写SQL语句的时候,没有主动指定使用哪个索引的话,用哪个索引是由MySQL来确定的。
我们日常不断地删除历史数据和新增数据的场景,有可能会导致MySQL选错索引。那么有哪些解决方案呢?
- 使用force index 强行选择某个索引
- 修改你的SQl,引导它使用我们期望的索引
- 优化你的业务逻辑
- 优化你的索引,新建一个更合适的索引,或者删除误用的索引。
2.2索引字段上使用is null, is not null,索引可能失效
2.3索引字段上使用(!= 或者 < >),索引可能失效
2.4对索引进行列运算(如,+、-、*、/),索引不生效
2.5 like通配符可能导致索引失效。
(3)limit分页问题
在系统中需要分页的操作通常会使用limit加上偏移量的方法实现,同时加上合适的order by 子句。如果有对应的索引,通常效率会不错,否则MySQL需要做大量的文件排序操作。
一个非常令人头疼问题就是当偏移量非常大的时候,例如可能是limit 10000,20这样的查询,这是mysql需要查询10020条然后只返回最后20条,前面的10000条记录都将被舍弃,这样的代价很高。
优化此类查询的一个最简单的方法是尽可能的使用索引覆盖扫描,而不是查询所有的列。然后根据需要做一次关联操作再返回所需的列。对于偏移量很大的时候这样做的效率会得到很大提升。.
(4)单表数据量太大
一个表的数据量达到好几千万或者上亿时,加索引的效果没那么明显啦。性能之所以会变差,是因为维护索引的B+树结构层级变得更高了,查询一条数据时,需要经历的磁盘IO变多,因此查询性能变慢。
一般超过千万级别,我们可以考虑分库分表了。
分库分表可能导致的问题:
- 事务问题
- 跨库问题
- 排序问题
- 分页问题
- 分布式ID
因此,大家在评估是否分库分表前,先考虑下,是否可以把部分历史数据归档先,如果可以的话,先不要急着分库分表。如果真的要分库分表,综合考虑和评估方案。比如可以考虑垂直、水平分库分表。水平分库分表策略的话,range范围、hash取模、range+hash取模混合等等。
(5)join 或者子查询过多
一般来说,不建议使用子查询,可以把子查询改成join来优化。而数据库有个规范约定就是:尽量不要有超过3个以上的表连接。为什么要这么建议呢? 我们来聊聊,join哪些方面可能导致慢查询吧。
MySQL中,join的执行算法,分别是:Index Nested-Loop Join和Block Nested-Loop Join。
Index Nested-Loop Join:这个join算法,跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引。
Block Nested-Loop Join:这种join算法,被驱动表上没有可用的索引,它会先把驱动表的数据读入线程内存join_buffer中,再扫描被驱动表,把被驱动表的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
join过多的问题:
一方面,过多的表连接,会大大增加SQL复杂度。另外一方面,如果可以使用被驱动表的索引那还好,并且使用小表来做驱动表,查询效率更佳。如果被驱动表没有可用的索引,join是在join_buffer内存做的,如果匹配的数据量比较小或者join_buffer设置的比较大,速度也不会太慢。但是,如果join的数据量比较大时,mysql会采用在硬盘上创建临时表的方式进行多张表的关联匹配,这种显然效率就极低,本来磁盘的 IO 就不快,还要关联。
一般情况下,如果业务需要的话,关联2~3个表是可以接受的,但是关联的字段需要加索引哈。如果需要关联更多的表,建议从代码层面进行拆分,在业务层先查询一张表的数据,然后以关联字段作为条件查询关联表形成map,然后在业务层进行数据的拼装。
文章来源:https://www.cnaaa.net,转载请注明出处:https://www.cnaaa.net/archives/4485

