

缓存雪崩
定义
缓存雪崩是指在短时间内,有大量缓存同时过期,导致大量的请求直接查询数据库,从而对数据库造成了巨大的压力,严重情况下可能会导致数据库宕机的情况叫做缓存雪崩。
正常情况下执行过程:


缓存雪崩下执行过程:
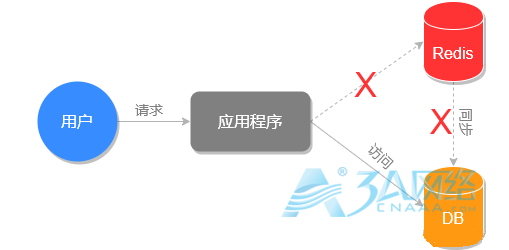
可以看到,当缓存失效时,大量请求直接绕过 Redis 去请求数据库,导致会对数据库造成很大压力。
解决
加锁排队
加锁排队可以起到缓冲的作用,防止大量的请求同时操作数据库,但它的缺点是增加了系统的响应时间,降低了系统的吞吐量,牺牲了一部分用户体验。
思路:当缓存未查询到时,对要请求的 key 进行加锁,只允许一个线程去数据库中查,其他线程等候排队,这里的加锁逻辑就类似于单例模式的双重校验锁。
代码实现:
// 缓存 key
String cacheKey = "userlist";
// 查询缓存
String data = jedis.get(cacheKey);
if (StringUtils.isNotBlank(data)) {
// 查询到数据,直接返回结果
return data;
} else {
// 先排队查询数据库,再放入缓存
synchronized (cacheKey) {
data = jedis.get(cacheKey);
if (!StringUtils.isNotBlank(data)) { // 双重判断
// 查询数据库
data = findUserInfo();
// 放入缓存
jedis.set(cacheKey, data);
}
return data;
}
}注意:如果是分布式架构,也就是服务集群,不能采用本地锁,必须得使用 Redis 的分布式锁。
随机化过期时间
为了避免缓存同时过期,可在设置缓存时添加随机时间,这样就可以极大的避免大量的缓存同时失效。
代码实现:
// 缓存原本的失效时间
int exTime = 10 * 60;
// 随机数生成类
Random random = new Random();
// 缓存设置
jedis.setex(cacheKey, exTime + random.nextInt(1000) , value);设置二级缓存
二级缓存指的是除了 Redis 本身的缓存,再设置一层缓存,当 Redis 失效之后,先去查询二级缓存。
例如可以设置一个本地缓存,在 Redis 缓存失效的时候先去查询本地缓存而非查询数据库。
本地缓存可以使用 Google 的 Guava Cache 进行设置,并有容量驱逐、时间驱逐策略,很优秀的一个缓存工具类。
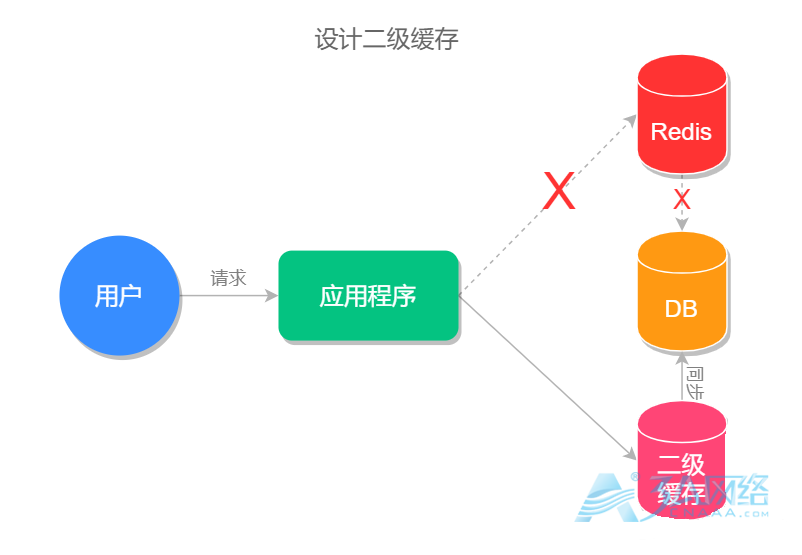
其实大部分情况下我们在项目中使用都是先访问本地缓存,然后再访问分布式缓存(Redis),因为访问本地缓存是最快的,没有网络开销,但是需要在一定的时间内进行更新,为了和分布式缓存中的数据保持一致。
缓存穿透
定义
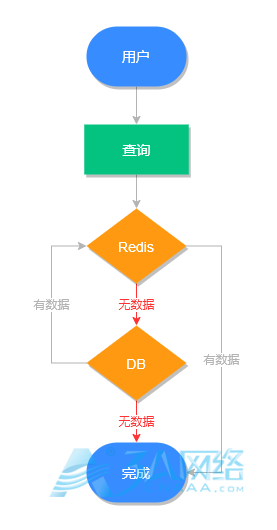
缓存穿透是指查询数据库和缓存都无数据,因为数据库查询无数据,出于容错考虑,不会将结果保存到缓存中,因此每次请求都会去查询数据库,这种情况就叫做缓存穿透。
解决
使用过滤器
我们可以使用布隆过滤器来减少对数据库的请求,布隆过滤器的原理是将数据库的数据哈希到 bitmap 中,每次查询之前,先使用布隆过滤器过滤掉一定不存在的无效请求,从而避免了无效请求给数据库带来的查询压力。
我们可以把每次从数据库查询的数据都保存到缓存中,为了提高前台用户的使用体验 (解决长时间内查询不到任何信息的情况),我们可以将空结果的缓存时间设置得短一些,例如 3~5 分钟。
缓存击穿
定义
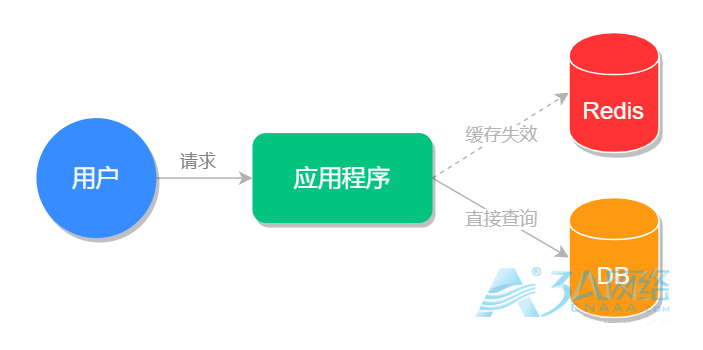
缓存击穿指的是某个热点缓存,在某一时刻恰好失效了,然后此时刚好有大量的并发请求,此时这些请求将会给数据库造成巨大的压力,这种情况就叫做缓存击穿。
解决
加锁排队
和缓存雪崩的加锁处理方式一致,再查数据库时进行加锁,缓冲大量请求。
设置永不过期
对于某些热点缓存,我们可以设置永不过期,这样就能保证缓存的稳定性,但需要注意在数据更改之后,要及时更新此热点缓存,不然就会造成查询结果的误差。
缓存预热
缓存预热并不是一个问题,而是使用缓存时的一个优化方案,它可以提高前台用户的使用体验。
缓存预热指的是在系统启动的时候,先把查询结果预存到缓存中,以便用户后面查询时可以直接从缓存中读取,以节约用户的等待时间。
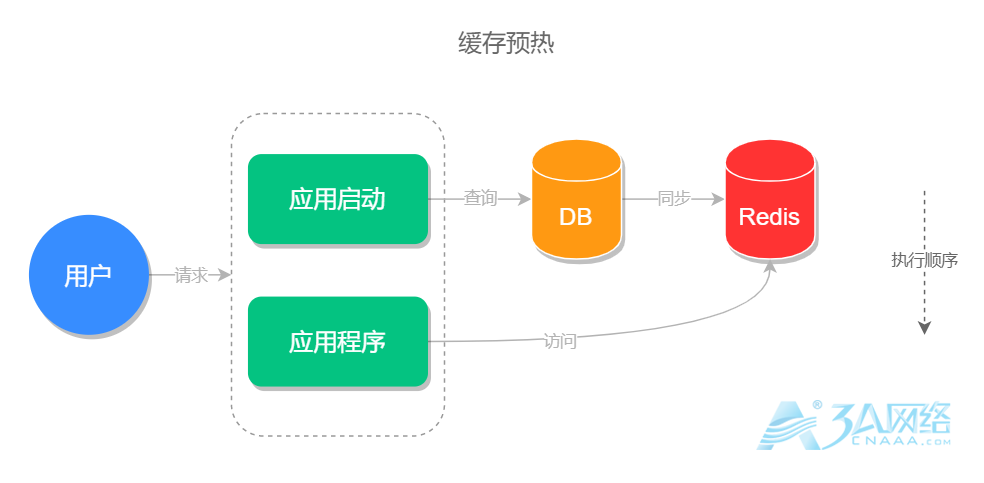
缓存预热的实现思路有以下三种:
- 把需要缓存的方法写在系统初始化的方法中,这样系统在启动的时候就会自动的加载数据并缓存数据。
- 把需要缓存的方法挂载到某个页面或后端接口上,手动触发缓存预热。
- 设置定时任务,定时自动进行缓存预热。
文章来源:https://www.cnaaa.net,转载请注明出处:https://www.cnaaa.net/archives/6121

