

因为在自测过程中,创建了很多数据库,一个个手动删除属实有点对不起程序员这个身份,那么有没有简单的sql语句操作来进行批量删除数据库呢?于是便有了本篇文章


思路
了解到数据库或表的信息都保存在MySQL内置的 information_schema数据库的SCHEMATA表中,因此是否可以通过like查询information_schema中的相关表名,拼接SQL,进行批量删除。
实操
批量删除数据库(以前缀为 ‘test_’ 示例)
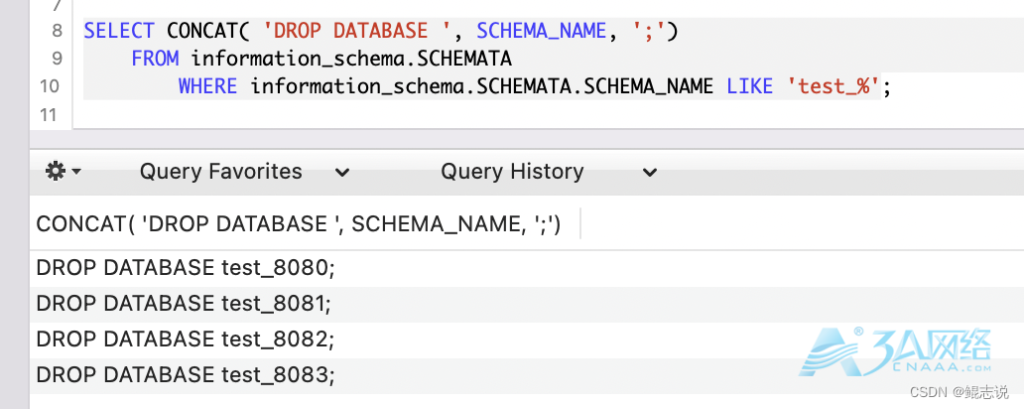
SELECT CONCAT( 'DROP DATABASE ', SCHEMA_NAME, ';')
FROM information_schema.SCHEMATA
WHERE information_schema.SCHEMATA.SCHEMA_NAME LIKE 'test_%';
如下图,查询结果是拼接好的sql,CV一下,执行即可
批量删除表(以前缀为 ‘df_’ 示例)
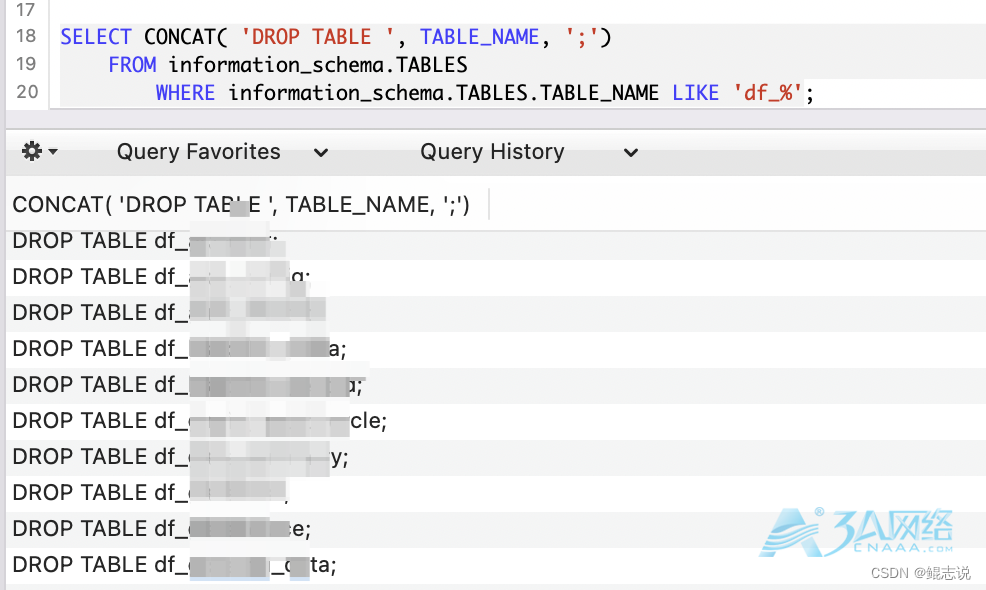
SELECT CONCAT( 'DROP TABLE ', TABLE_NAME, ';')
FROM information_schema.TABLES
WHERE information_schema.TABLES.TABLE_NAME LIKE 'df_%';
如下图,同样查询结果是拼接好的sql,CV一下,执行即可
到这里已经实现了批量删除操作,下面是引发的探究,如时间紧张可先赞后看,保持良好习惯!
MySQL 5.7 自带的四个数据库
在Mysql5.7版本中自带4个数据库:information_schema、mysql、performance_schema、sys。

mysql
mysql的核心数据库,类似于sql server中的master表,主要负责存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息。(常用的如在mysql.user表中修改root用户的密码)
performance_schema
主要用于收集数据库服务器性能参数。并且库里表的存储引擎均为PERFORMANCE_SCHEMA,而用户是不能创建存储引擎为PERFORMANCE_SCHEMA的表。MySQL5.7默认是开启的。
sys
sys库所有的数据源来自:performance_schema。目标是把performance_schema的复杂度降低,让DBA能更好的阅读这个库里的内容。让DBA更快的了解DB的运行情况。
information_schema
提供了访问数据库元数据的方式。(元数据是关于数据的数据,如数据库名、表名、列的数据类型和访问权限等。有时用于表述该信息的其他术语包括“数据词典”和“系统目录”) 该位置存储有关MySQL服务器维护的所有其他数据库的信息。
information_schema数据库表简介
该INFORMATION_SCHEMA数据库包含几个只读表。它们实际上是视图,而不是基表,因此没有与它们关联的文件,并且不能在它们上设置触发器。另外,没有使用该名称的数据库目录。虽然你可以选择INFORMATION_SCHEMA与一个默认的数据库USE 语句,你只能读取表的内容,不能执行 INSERT、UPDATE或 DELETE。
对于大多数INFORMATION_SCHEMA表,每个MySQL用户都有权访问它们,但只能看到表中与用户具有适当访问权限的对象相对应的行。在某些情况下(例如,表中的ROUTINE_DEFINITION列 INFORMATION_SCHEMA ROUTINES),特权不足的用户会看到NULL。某些表具有不同的特权要求;为此,在适用的表格说明中提到了这些要求。例如,InnoDB表(名称以开头的表INNODB_)需要PROCESS特权。
分表
information_schema库共计有61张表。下面仅以批量删除数据库和表涉及到分表展开简单介绍
SCHEMATA表
模式是数据库,因此 SCHEMATA表提供了有关数据库的信息。该SCHEMATA表包含以下列:
CATALOG_NAME:模式所属的目录的名称。此值始终为def
SCHEMA_NAME:模式的名称
DEFAULT_CHARACTER_SET_NAME:架构默认字符集
DEFAULT_COLLATION_NAME:模式默认排序规则
SQL_PATH:此值始终为NULL
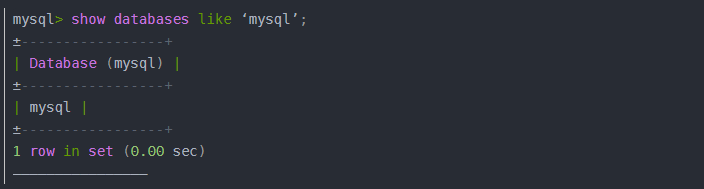
模式名称也可以从该SHOW DATABASES语句中获得:
TABLES表
该TABLES表提供有关数据库中表的信息。该TABLES表包含以下列:
TABLE_CATALOG:该表所属的目录的名称。此值始终为def。
TABLE_SCHEMA:表所属的模式(数据库)的名称。
TABLE_NAME:表的名称。
TABLE_TYPE:BASE TABLE为一个表、 VIEW用于一个视图、SYSTEM VIEW为一个INFORMATION_SCHEMA 表。该TABLES表未列出 TEMPORARY表。
ENGINE:表的存储引擎。对于分区表,ENGINE显示所有分区使用的存储引擎的名称。
VERSION:表.frm 文件的版本号。
ROW_FORMAT:该行的存储格式(Fixed, Dynamic,Compressed, Redundant,Compact)。对于 MyISAM表,Dynamic 对应于myisamchk -dvv报告为的内容Packed。InnoDB表格式可以是Redundant或者
Compact使用时的 Antelope文件格式,或者 Compressed或Dynamic 使用时Barracuda的文件格式。
TABLE_ROWS:行数。一些存储引擎(例如 MyISAM)存储准确的计数。对于其他存储引擎(例如)InnoDB,该值是一个近似值,可能与实际值相差40%至50%。在这种情况下,请使用SELECT
COUNT(*)以获得准确的计数。 TABLE_ROWS是NULL对 INFORMATION_SCHEMA表。
对于InnoDB表,行数只是SQL优化中使用的粗略估计。(如果InnoDB表已分区,则也是如此。)
AVG_ROW_LENGTH:平均行长。
DATA_LENGTH 对于MyISAM,DATA_LENGTH 是数据文件的长度(以字节为单位)。 对于InnoDB,DATA_LENGTH
是为聚簇索引分配的大约空间量(以字节为单位)。具体来说,它是聚簇索引大小(以页为单位)乘以InnoDB页面大小。
MAX_DATA_LENGTH 对于MyISAM, MAX_DATA_LENGTH是数据文件的最大长度。给定使用的数据指针大小,这是表中可以存储的数据字节总数。 未使用InnoDB。
INDEX_LENGTH 对于MyISAM,INDEX_LENGTH 是索引文件的长度(以字节为单位)。 对于InnoDB,INDEX_LENGTH
是为非聚簇索引分配的大约空间量(以字节为单位)。具体来说,它是非聚集索引大小(以页为单位)的总和乘以 InnoDB页面大小。
DATA_FREE 已分配但未使用的字节数。 InnoDB表报告表所属的表空间的可用空间。对于位于共享表空间中的表,这是共享表空间的可用空间。如果您使用多个表空间,并且表具有自己的表空间,则可用空间仅用于该表。可用空间是指完全可用范围中的字节数减去安全裕量。即使可用空间显示为0,只要不需要分配新的盘区,也可以插入行。
对于NDB群集,DATA_FREE显示磁盘上为磁盘上的磁盘数据表或碎片分配但未使用的空间。(该DATA_LENGTH列中报告了内存中数据资源的使用情况。)
对于分区表,此值仅是估计值,可能不是绝对正确。在这种情况下,获取此信息的一种更准确的方法是查询 INFORMATION_SCHEMA
PARTITIONS表,如本示例所示:
SELECT SUM(DATA_FREE) FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_SCHEMA = ‘mydb’ AND TABLE_NAME = ‘mytable’;
AUTO_INCREMENT:下一个AUTO_INCREMENT值。
CREATE_TIME:创建表的时间。
UPDATE_TIME 数据文件的最后更新时间。对于某些存储引擎,此值为NULL。例如, InnoDB将多个表存储在其 系统表空间中,并且数据文件时间戳不适用。即使 文件每次表模式与每个InnoDB在单独的表 .ibd文件, 改变缓冲
可以延缓写入到数据文件,因此,文件的修改时间是从最后插入,更新或删除的时间不同。对于MyISAM,使用数据文件时间戳;但是,在Windows上,时间戳不会通过更新进行更新,因此该值不准确。
UPDATE_TIME显示last UPDATE, INSERT或 DELETE对InnoDB未分区表执行
的时间戳记值。对于MVCC,时间戳记值反映了
COMMIT时间,该时间被视为最后更新时间。重新启动服务器或从InnoDB数据字典缓存中删除表时,时间戳记不会保留。
该UPDATE_TIME列还显示了分区InnoDB表的此信息。
CHECK_TIME 上次检查表的时间。并非所有存储引擎这次都更新,在这种情况下,该值始终为 NULL。 对于分区InnoDB表, CHECK_TIME始终为 NULL。
TABLE_COLLATION:该表的默认排序规则。输出没有显式列出表的默认字符集,但是排序规则名称以字符集名称开头。
CHECKSUM:实时校验和值(如果有)。
CREATE_OPTIONS 与一起使用的额外选项CREATE TABLE。 CREATE_OPTIONS显示 partitioned表是否已分区。 CREATE_OPTIONS显示ENCRYPTION为在每个表文件表空间中创建的表指定的 子句。
在禁用严格模式的情况下创建表时 ,如果不支持指定的行格式,则使用存储引擎的默认行格式。表的实际行格式在ROW_FORMAT
列中报告。CREATE_OPTIONS显示CREATE TABLE语句中指定的行格式。
更改表的存储引擎时,不适用于新存储引擎的表选项将保留在表定义中,以便在必要时将具有其先前定义的选项的表恢复到原始存储引擎。该CREATE_OPTIONS列可能显示保留的选项。
TABLE_COMMENT:创建表时使用的注释(或有关MySQL为什么无法访问表信息的信息)
文章来源:https://www.cnaaa.net,转载请注明出处:https://www.cnaaa.net/archives/10655

